


Which LLM is the Conversation Champ?
Compare LLMs in long conversations



Two days ago, OpenAI released a new model: GPT-4o-mini, a cost-effective yet highly intelligent model boasting excellent performance metrics compared to the advanced large models available today. This wave of new Large Language Models (LLMs) has sparked widespread excitement. Intrigued by these developments, we set out to discover which model could truly engage in human-like conversations, far beyond just answering a single question.
We are eager to explore how these seemingly intelligent options compare when it comes to sustaining long conversations.
1. Long conversations and LLMs
Long conversations can be tough, even for the most attentive humans. Staying focused and retaining information becomes a real challenge with frequent topic shifts and information overload. Maintaining a balanced and productive dialogue demands continuous effort, often diminishing its effectiveness over time.
We are excited to see how Large Language Models (LLMs) perform in this arena, particularly popular choices like ChatGPT, Gemini, and Anthropic Claude. To evaluate their abilities, we’ve crafted a series of tests to determine how well these LLMs can take on roles and sustain engaging, human-like conversations over extended periods.
2. Who is doing better?
Our experiments reveal that GPT-4o delivered the most consistent and responsive results. According to our metrics, it is the best LLM for emulating human-like conversations over extended periods. GPT-4o consistently excelled in long conversations, with GPT-4 Turbo and GPT-4o-Mini following closely behind. Interestingly, GPT-4 Turbo surpassed GPT-4o in some character-specific scenarios. Claude (Opus) also performed well but took significantly longer than the GPT models to generate responses.
When it comes to acting in roles, giving instructions, and asking questions, Claude (Opus) stands out for its response length. Despite prompts requesting only two sentences per response (which most models tend to exceed), Claude often generates two to three times as many words as the other models with the same prompt. This verbose style can lead to repetition, but the quality of Claude’s responses is on par with, or even better than, GPT-4 and GPT-4o. Claude’s generated conversations exhibit the most natural, non-robotic responses, with unique insights and comments not found in other models.
In our tests on creating custom characters with emotions, Gemini struggled to generate complete conversations due to messages that flagged its own safety guidelines. As a result, Gemini was excluded from the final results for this test.
Overall, GPT-4o proves to be the best at maintaining long, human-like conversations, while Claude excels in producing insightful and naturally flowing dialogue despite its verbosity.
3. Methodology and Experiments
To rate a conversation, we need robust parameters that provide a final score for the LLM actor. To determine just how good of an actor an LLM is, we implemented five key categories: tone, contextual relevance, consistency, naturalness, and repetition. We also measure response speed because lagging replies can disrupt the entire conversation experience.
We employ GPT-4o to generate a score between 0 and 100, assessing the LLM actor’s performance. For repetition, we analyze Ngram overlap for all messages sent by the LLM and use VoyageAI’s embedding model to compare individual utterances. For custom character analysis, this repetition score is factored into the overall average of all categories.
We fed the models complex system prompts, specifying particular emotions within various scenarios. To gather diverse data, we tested a wide range of emotions such as defensiveness, frustration, anger, and manipulation. Additionally, we designed an experiment focused on giving consistent instructions and feedback to conduct a fine-grained repetition analysis.
By running these tests and scoring the metrics, we collected a comprehensive set of results, revealing how well each model could sustain engaging, human-like conversations across different emotional states and scenarios.
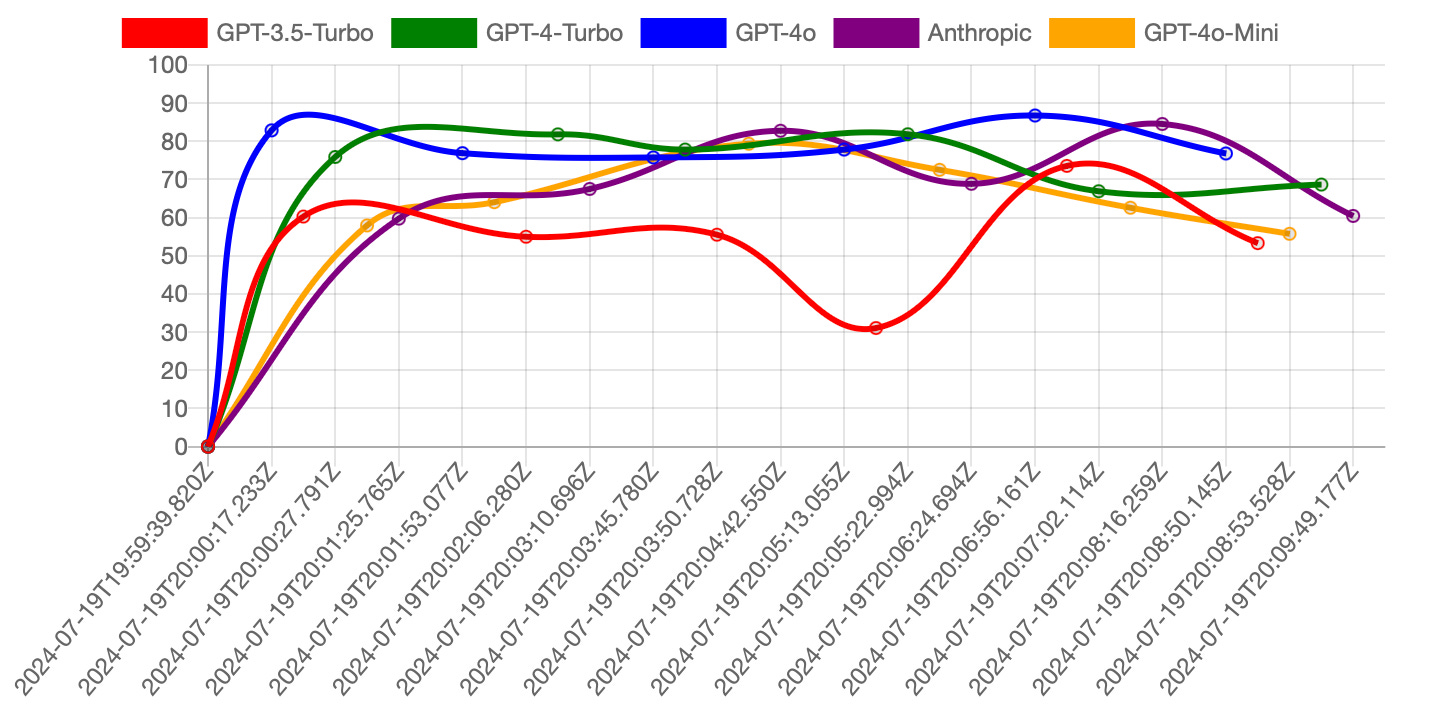
Here’s a chart showcasing how the bot emulates the emotion of frustration. The Y-axis represents a composite score (the higher, the better) indicating the bot’s performance in long conversations. Each dot on the chart represents a set of long conversations, providing a visual insight into how well and how fast the bot navigates this complex emotion.
And here’s a chart that measures a bot’s repetitiveness in providing instructions and feedback on a scenario to give instructions and feedback. The Y-axis displays a score (the lower, the better) indicating how often the bot repeats itself in conversations. Each dot represents a round of long conversation, providing a clear visual of the bot’s ability to keep responses fresh and varied.

Sometimes, just one repeated comment or question can throw off the vibe of a long conversation. That’s why we also measure ‘Peak Repetition’ – the worst instance of repetition. In this metric, GPT-4o-mini truly shines, outperforming all other models by keeping repetition to a minimum and maintaining a more engaging dialogue.

4. What’s next?
GPT-4o is currently the best “actor” we have. While other models are hot on its heels, GPT-4o reigns supreme in consistency and speed. However, we acknowledge that this test isn’t perfect—using GPT-4o to grade other LLMs might introduce some bias towards what constitutes a “good” result in each category. Looking ahead, we believe that incorporating a much larger grading scale, where every LLM grades the same conversation, and introducing a broader set of “human-like” metrics, will help eliminate this bias and provide a more objective analysis. We are excited to continue unveiling our findings on the next wave of groundbreaking models.
About authors:

a rising sophomore at New York University, passionate about creating exceptional user experiences across various media.

a rising senior at Cornell University, immersing himself in building AI applications this summer.

Appendix
*Final Culminated Scores on emotion consistency:
GPT-3.5: 44.7
GPT-4: 76.1
GPT-4o: 76.6
GPT-4o-Mini: 69.2
Claude: 67.6
*Final Culminated Scores on peak repetitiveness:
GPT-3.5: 84
GPT-4: 79.4
GPT-4o: 75.8
GPT-4o-mini: 73.8
Claude-Sonnet: 86.8
Gemini-1.5: 79.2